Working with HTTP in Polynote
Polynote is a recently open-sourced, polyglot notebook with support for Scala, Spark, Python and SQL. While notebooks are most often used for big data, machine learning and data science, from time to time you still need to do an HTTP request, fetch some JSON, parse and explore it.
How can we send an HTTP request from a polynote notebook? Since we’re dealing with Scala, we’ll use the sttp client, in a REPL/notebook-friendly form.
Let’s start by downloading the most recent polynote release and unpacking it. Then we can either add the sttp dependencies as a default for all notebooks, by copying config-template.yml to config.yml and adding a dependencies section:
dependencies:
scala:
- com.softwaremill.sttp.client:okhttp-backend_2.11:2.0.0-RC1
- com.softwaremill.sttp.client:circe_2.11:2.0.0-RC1
- io.circe:circe-generic:0.11.1Or, by running ./polynote, creating a new noteboook and adding the dependencies in the “Configuration & dependencies” section (which is folded by default):

We’ll be using the sttp client API with OkHttp as the backend, as it provides a synchronous backend (Futures and IOs are great, but not in a notebook setting), and is based on a stable and battle-proven library. Moreover, to parse JSON, we’ll be using circe.
Now that we’re ready, we can start notebooking! First, we need some imports:

We’ll need three imports to work comfortably:
- first,
import sttp.client.okhttp.quick._. This pulls in the sttp client API, an implicit instance of a synchronous backend, as well asquickRequest: a starting point for describing requests, which will always read the response body as aString.
In an application, you’ll probably want to
import sttp.client._and create the backend yourself, as that gives you control over allocation of resources (creating the backend and the connection pool). Moreover, you’ll most likely usebasicRequestas a starting point, which by default reads the response body into anEither[String, String],RightorLeftdepending on the status code, so that you get some more type-safety in the unsafe HTTP world.
- second,
import sttp.client.circe._pulls in sttp-circe integration, so we can parse response bodies as JSON - finally,
import io.circe.generic.auto._will automatically derive JSON codecs for case classes (when possible), so that we don’t have to write them by hand
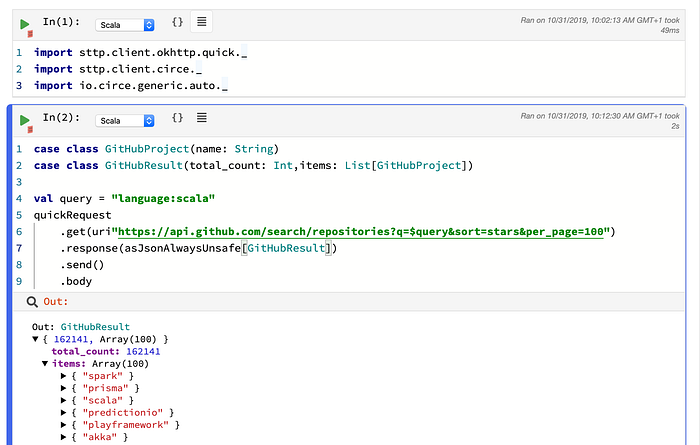
We can now run our first request! Let’s try a very simple one.

Seems to work. Next, let’s try parsing some JSON, and visualising the results. We’ll query the GitHub API and look for Scala repositories sorted by star count:

As you can see, we can (safely) embed values in the URI, thanks to the
uriinterpolator. The interpolator not only handles context-sensitive encoding, but also supportsOptional values, collections, parameter maps etc.
The result is a large JSON — let’s try parsing it! We have several options; we can parse the String into circe’s Json type, which represents arbitrary JSON. This datatype can be then traversed, also using a dedicated optics module.
Here, however, we’ll parse the response into a data structure. We’ll be only interested in repository names. Looking at the result, we can see that there’s an items array, each containing the data for one project. Our data structure will then be:
case class GitHubProject(name: String)
case class GitHubResult(total_count: Int,items: List[GitHubProject])How can we read the response as json? We’ll modify the description of the request, so that it contains information on how the response should be handled. Here, we’ll use the already imported sttp.client.circe.asJson, which comes from the sttp-circe integration. JSON codecs will also be automatically generated, so we don’t need to add anything more:
As we’re in a notebook environment, we don’t worry too much about HTTP or deserialisation errors, and that’s why we use
asJsonAlwaysUnsafe, which will throw an exception if the JSON can’t be fetched or parsed. In an application, you’ll probably want to useasJson, which is more type-safe, and returnsEithera deserialisation error, or the result.
Now that we have our big data (top 100 Scala projects), we can do some data science! Let’s see what the most popular initial letter for a scala project is (can you guess?).
To do that, we’ll group our responses by the first letter of the project’s name, and count how many projects there are in each group:
Finally, we can visualise our result:
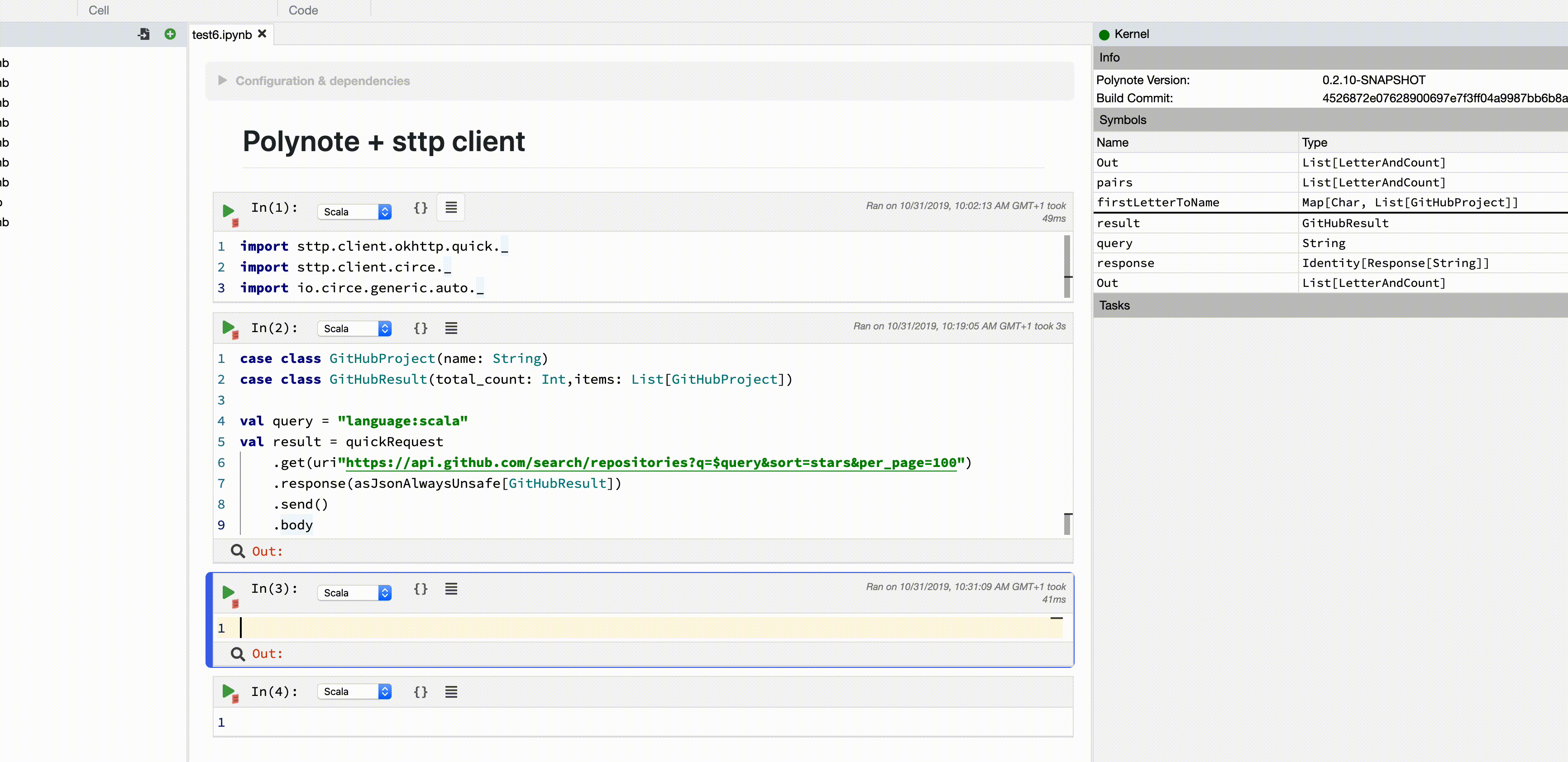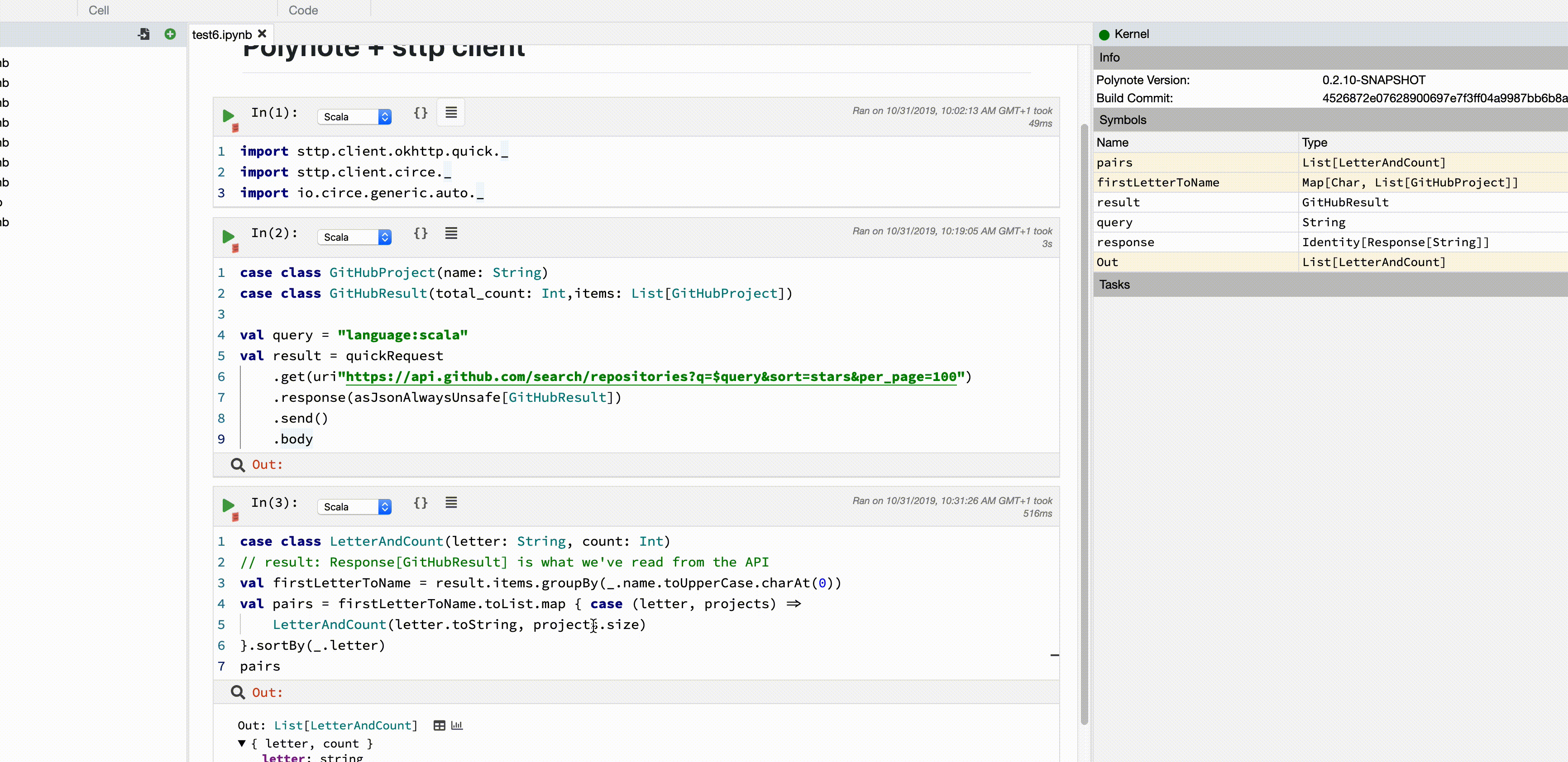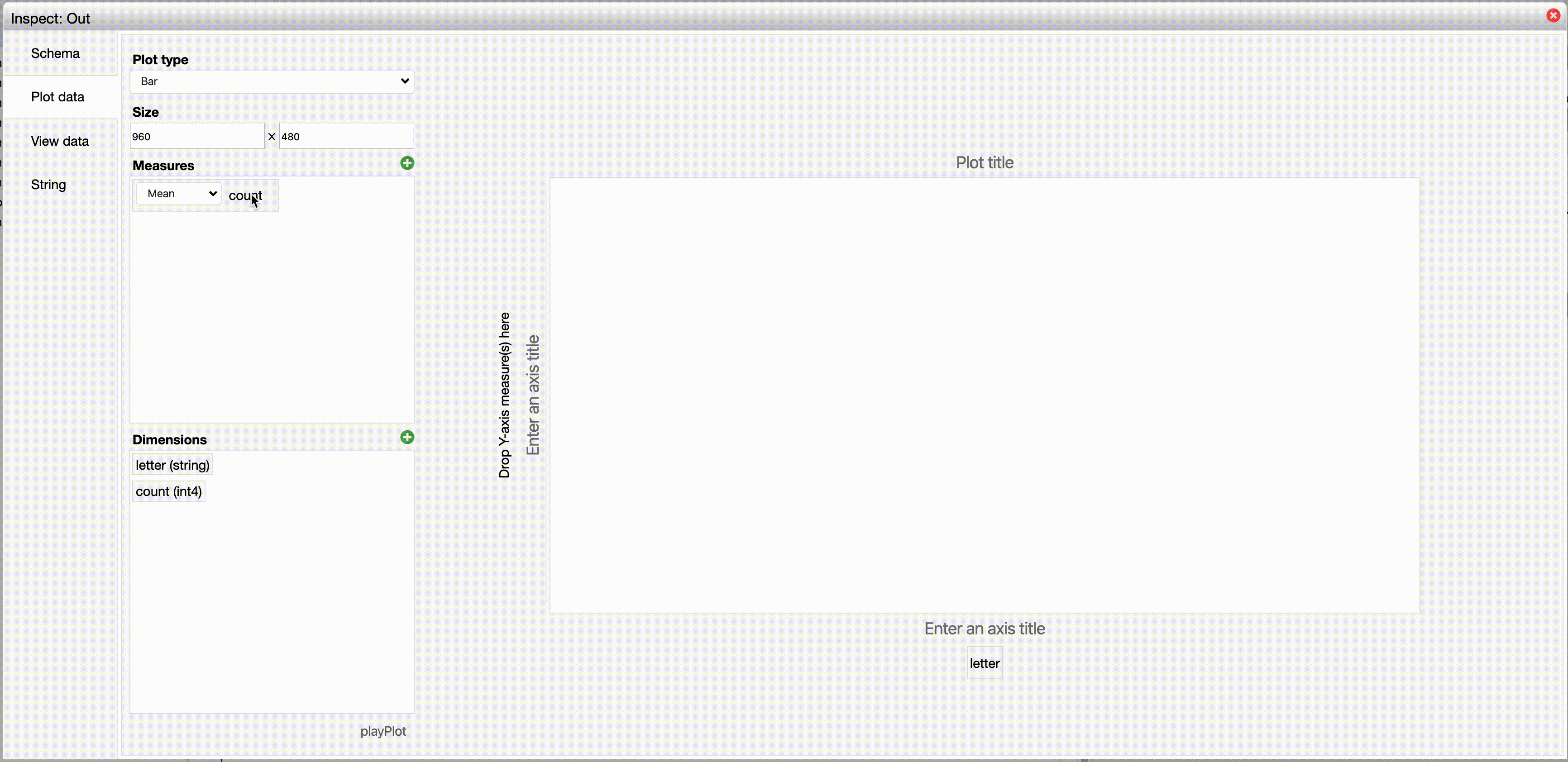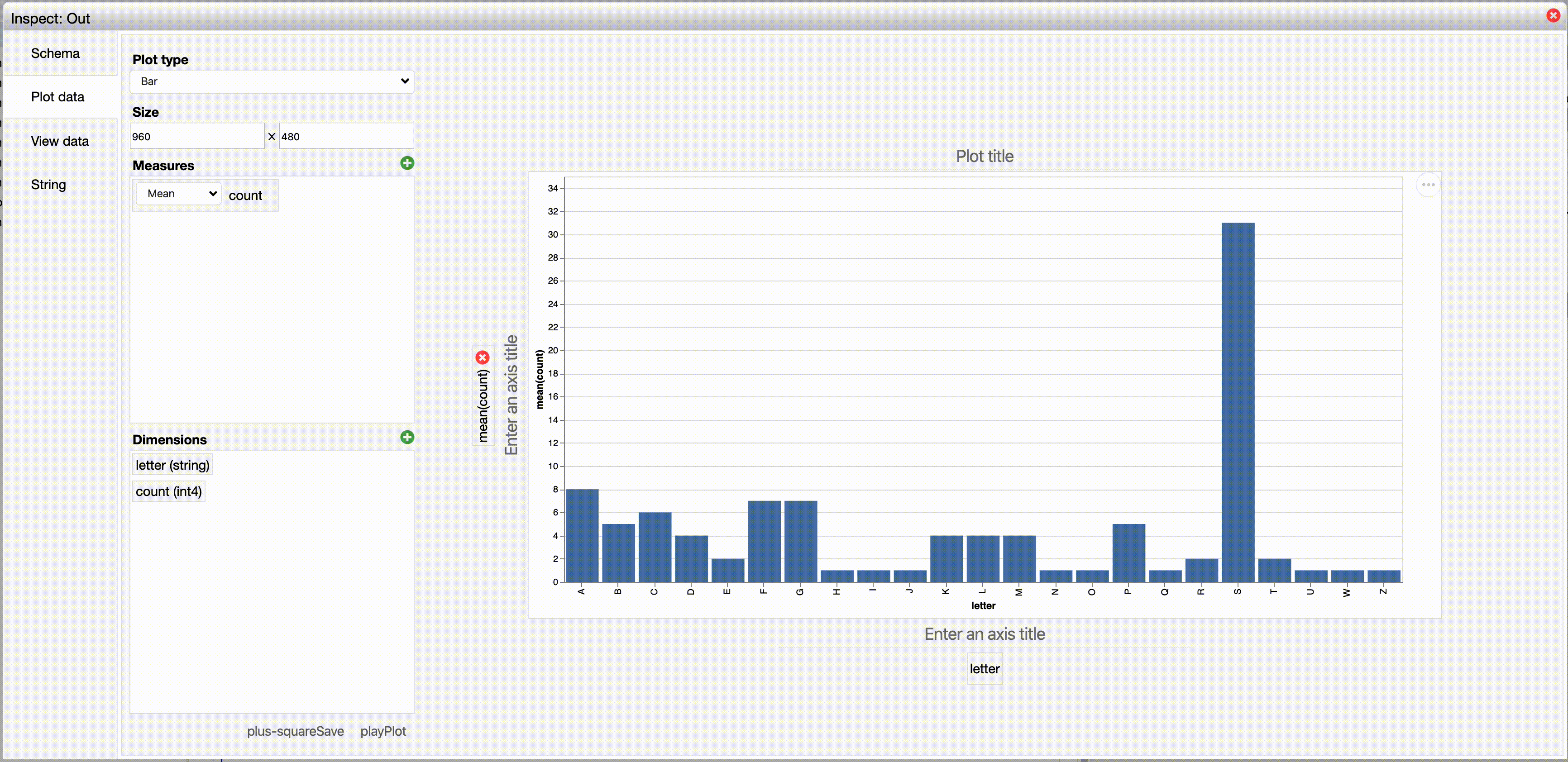
Sis, without much surprise, the most popular initial letter for a Scala project with a lot of stars.
You can find out more about polynote and sttp client on their websites. And here’s the full notebook. Enjoy!