How to deal with more than 2 billion records in the SQL database?
One of our customers had a problem with a large MySQL table with over 2 billion records, which was continuously growing. Without replacing the infrastructure, there was a danger of running out of disc space which could potentially break the whole application. There were also other issues with such a big table: poor query performance, bad schema design, and — due to the fact that there were so many records — there was no easy way of analysing such a large amount of data. First of all, we wanted to create a solution that would fix these problems but without the need to introduce a costly maintenance window when the application is not working and customers cannot use it. In this blog post, I would like to describe our approach to this problem but I would also like to mention that this is not a recommendation: each case is different and needs different solutions, but maybe someone will get some valuable insights after reading how we dealt with this issue.

Cloud to the rescue?
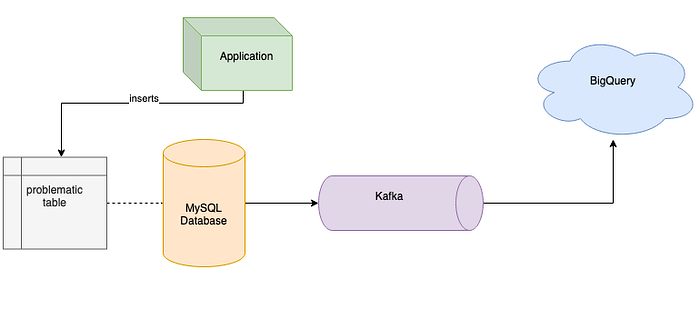
After evaluation of a few alternative solutions, we decided to stream this data to some cloud solution and our choice was Google Big Query. We decided to use it because our customer preferred cloud solutions from Google, the data that we wanted to stream was structured and analytical, and we didn’t need low latency, so BigQuery seemed to be a perfect fit (see the diagram below). After our tests about which you can read in Andrzej Ludwikowski’s post, we were sure that Big Query is a good enough solution that meets our customer needs and allows them to use analytical tools in order to analyse data in just a few seconds. But, as you may already know, making a lot of queries could generate big costs in BigQuery so we wanted to avoid querying with the application itself and we used BigQuery only as an analytical tool and some kind of backup.
Streaming data to the cloud
If you are thinking about streaming data, there are of course many ways of doing this, but in our case, the choice was very simple. We’ve used Apache Kafka , simply because we are already using it widely in the project and there was no need for introducing another solution. Using Kafka for streaming gave us yet another advantage — we could stream all the data to Kafka and keep it for the required time and then use it to migrate it into the desired solution that would deal with all problems that we had, without putting a big load on MySQL cluster. This approach has given us some sort of fallback in case of failure with the usage of BigQuery, such as too high costs or difficulties in executing requested queries. As you will see later in this post, this was a crucial decision that gave us a lot of benefits with a little overhead.
Streaming from MySQL
So when you’re thinking about streaming from MySQL to Kafka you are probably thinking about Debezium or Kafka Connect. Both solutions are great choices but in our case, there was no way of using them. The MySQL server version was so old that Debezium was no longer supporting it and upgrading MySQL wasn’t an option. We also could not use Kafka Connect either because of the lack of auto increment column in that table that could be used by the connector to query for new records without losing any of them. We knew that there is a possibility to use timestamp columns but another problem with this approach was that some rows could be lost because the query was using lower timestamp precision than was defined in the table column. Of course, both solutions are good, and if there are no contradictions against using them in your project I could recommend them as tools that could stream data from your database to Kafka. In our case, we needed to develop a simple Kafka producer that was responsible for querying data without losing any records and streaming it into Kafka, and another consumer that sends data to BigQuery, which was visualized below in a simple diagram.
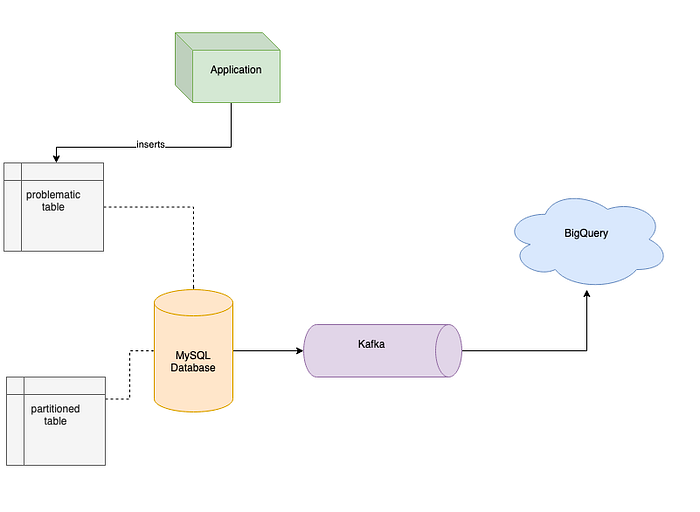
Partitioning as a way of reclaiming space
So we streamed all the data to Kafka (we have used compression in order to reduce payload) and then later to BigQuery which helped us fixing query performance issues allowing us to analyse a lot of data in just a few seconds but the problem with space remained. We wanted to design a solution that resolves the problem now and could be easily used in the future. We started with preparing a new schema of that table, a schema that could use serial id as primary key and also would use partitioning where rows would be partitioned by month. Partitioning this big SQL table could give us the ability to backup old partitions and truncate/drop them in order to reclaim some space after the partition is not needed anymore. So we created a new table with a new schema and used data from Kafka to populate this new partitioned table. After migrating all the records we deployed a new version of the application that used a new table with partitioning for inserts and we dropped the old table in order to reclaim the space. Of course, you will need to have enough free space in order to migrate old data into the new table, but in our case, we were continuously making backups and truncating old partitions during migration just to be sure that we have enough space for new data.
Compacting as another way of reclaiming space
As I already mentioned, after streaming data to BigQuery we could easily analyse the whole dataset and this gave us the ability to verify a few new concepts that could allow us to reduce space occupied by the table in the database. One of the ideas was the proposition to verify how different types of data are distributed across the table. After making some queries the brutal truth was revealed that almost 90% of the data is not needed anymore for anybody, so we decided to compact the data simply by writing a new Kafka consumer which would filter out unwanted records and insert only needed ones to yet another table. Let’s call it a compacted table, which was illustrated in the below gist and in the diagram.
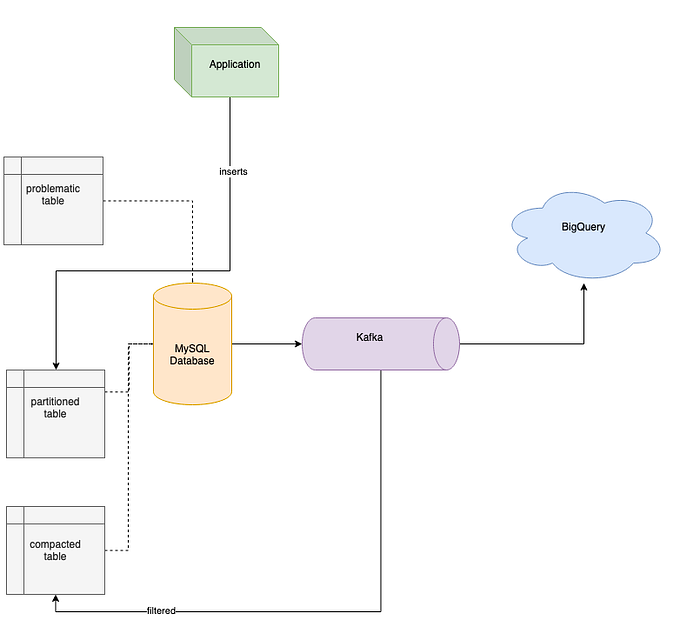
After data was compacted, we could update our application in order to do reads from the new table — the compacted table — and separate writes by using the table from the previous paragraph — the partitioned table — from which we are continually streaming data with Kafka into the compacted table. So as you can see, the problems that our customer was facing were fixed by the above solutions. Thanks to partitioning, lack of space isn’t a problem anymore, compacting and proper indexes design resolved some issues with query performance that come from the application and lastly, streaming all the data to the cloud gave our customer the ability to easily analyse all the data. And since we are using BigQuery only for specific analytic queries, and the rest of application-related queries that came from the users are still executed by MySQL server, the costs are not as high as you might expect. The other important thing is the fact that all these operations were done without any downtime, so customers were not affected.
Summary
So to summarize, we started by using Kafka as a tool to stream data into BigQuery but since we streamed all the data to Kafka this gave us space to easily develop other solutions so that we could resolve relevant issues that were important for our customer without worrying that something might go wrong.